Invoice Data Extraction: Traditional OCR vs Vision LLMs
March 4, 2025· Amol Walunj, Vedant
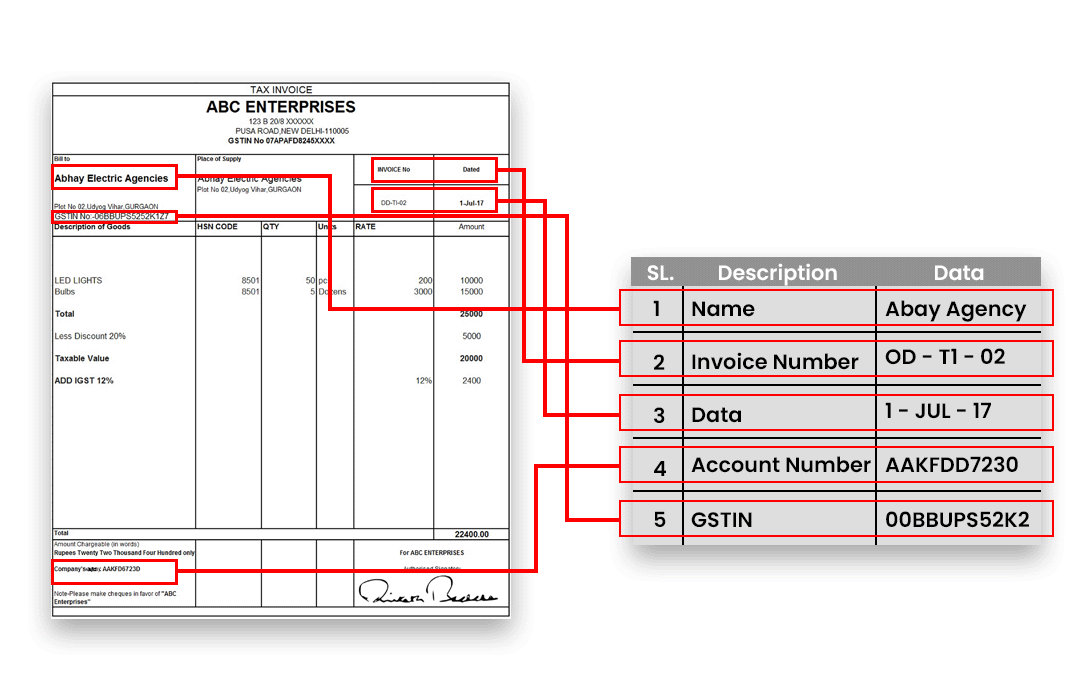
Introduction
Invoice processing is a crucial aspect of business operations, particularly for financial reconciliation, vendor management, and compliance. Automating invoice extraction helps reduce manual errors, improves efficiency, and enables better data integration.
Traditional OCR-based methods using RPA (Robotic Process Automation) or machine learning (ML) have been widely used for invoice extraction. However, with the emergence of Vision LLMs, the paradigm has shifted towards more accurate and scalable solutions.
Problem Statement
Extracting structured information from invoices is complex due to:
- Variability in invoice layouts: Different vendors use unique formats, making template-based extraction unreliable.
- OCR inaccuracies: Poor text extraction due to low-quality scans, handwritten invoices, or complex layouts.
- Scalability issues: Traditional ML-based approaches require retraining for new invoice formats.
Challenges in Solving the Problem
1. OCR Limitations
- Struggles with misalignment, low resolution, and complex multi-column layouts.
- Extracted text lacks structural understanding.
2. Template Dependency
- Rule-based approaches work only for known formats, making adaptation to new formats challenging.
3. Data Structuring Complexity
- Requires additional processing steps (regex, heuristics, ML models) to extract and classify key fields.
4. Scalability and Maintenance
- Adding new formats means manually defining new rules or retraining ML models.
Current Solutions and Their Limitations
Traditional OCR-Based RPA Pipelines
- Utilize Tesseract OCR or Google Vision OCR to extract text.
- Apply regex-based or rule-based methods to extract fields like invoice number, date, and total amount.
- Limitations: Template rigidity, poor text structuring, and high maintenance costs.
Machine Learning-Based Approaches
- Utilize Named Entity Recognition (NER) or deep learning models to classify extracted fields.
- Limitations: Requires labeled training data, struggles with unseen layouts.
Proposed Solution: Vision LLMs for Invoice Extraction
With Vision LLMs (like GPT-4V, Claude 3.5 Vision, or LLaVa), invoice extraction becomes more accurate and scalable:
- OCR-free or enhanced OCR-based processing
- Context-aware key field extraction
- Generalization across multiple layouts without predefined templates
Code Tutorial: Comparative Analysis
We compare:
- Tesseract OCR + Regex (Traditional Approach)
- GPT-4V (Vision LLM) for direct extraction
Traditional OCR + Regex Approach
import cv2
import pytesseract
import re
def extract_invoice_fields(image_path):
# Read image
img = cv2.imread(image_path)
# Apply OCR
extracted_text = pytesseract.image_to_string(img)
# Extract key fields using regex
invoice_number = re.search(r'Invoice\s*No[:\-]\s*(\d+)', extracted_text)
invoice_date = re.search(r'Date[:\-]\s*(\d{2}/\d{2}/\d{4})', extracted_text)
total_amount = re.search(r'Total[:\-]\s*\$?(\d+\.\d{2})', extracted_text)
return {
"Invoice Number": invoice_number.group(1) if invoice_number else "Not Found",
"Invoice Date": invoice_date.group(1) if invoice_date else "Not Found",
"Total Amount": total_amount.group(1) if total_amount else "Not Found"
}
# Example usage
invoice_data = extract_invoice_fields("invoice_sample.jpg")
print(invoice_data)
Limitations:
- Works only for invoices that match regex patterns.
- Fails with non-standard layouts.
Vision LLM-Based Approach (GPT-4V or Claude 3.5 Vision)
import openai
def extract_invoice_with_gpt4v(image_path):
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[
{"role": "system", "content": "Extract invoice fields such as invoice number, date, and total amount."},
{"role": "user", "content": {"image": image_bytes, "type": "image/jpeg"}}
]
)
return response["choices"][0]["message"]["content"]
# Example usage
invoice_data = extract_invoice_with_gpt4v("invoice_sample.jpg")
print(invoice_data)Advantages:
- No need for regex or predefined patterns.
- Works on various invoice layouts.
- More accurate and context-aware extraction.
Comparison of Results
Method
Accuracy
Adaptability
Response Time
Tesseract + Regex
70-80%
Low
Fast (~1s)
GPT-4V (Vision LLM)
95%+
High
Moderate (~3s)
Conclusion
- Traditional OCR-based methods work well for fixed templates but struggle with new formats.
- Vision LLMs provide superior accuracy and adaptability, reducing the need for custom rules.
- Future Scope: Fine-tuning vision models for domain-specific invoice processing.
Vision LLMs represent the future of intelligent document processing, making invoice extraction more scalable and efficient.
At Cogninest AI, we specialize in helping companies build cutting edge AI solutions. To explore how we can assist your business, feel free to reach out to us at team@cogninest.ai