How AI Language Models Are Decoding Visual Content
April 4, 2025· Amol Walunj, Vedant Mayekar

How LLMs Are Transforming Image to Text Analysis with AI
Introduction:
- For a very long time, we have been using images to store vital information, be it screenshots of some important text or tabular data or its different Excel dashboard analysis.
- Yet extracting that information from it without any human help was almost impossible for a very long time/ In the past few years some techniques were introduced like OCR (optical character recognition).
- However, this approach had its limitations. It gave some results, but it was far from the accuracy and efficiency that we as humans needed. Also, as the technology and business involved the image started getting more and more complex due to higher data/text in an image, variation in lighting, and sheer diversity of visual content presented significant hurdles.
- This particular duration underscored the fundamental difficulty of bridging the gap between raw and visual data and actionable insights. Setting the stage for the transformative impact of AI.
Rise of AI in Computer Vision:
- The introduction of artificial intelligence, particularly the very rise in computer vision techniques had a significant turning point in image analysis. Advanced approaches were introduced for image analysis which helped in specific tasks such as object detection, facial recognition, and basic scene understanding.
- All these tasks had their place in different businesses as per their use cases. Each organization or business started using this application for analyzing the image and started integrating it to make them more efficient and cost-effective.
- However, they were far from being working completely independently. These approaches or models were built only to perform a specific task and were not able to perform other tasks. Often these approaches or applications were supposed to be supervised by a highly trained engineer or person. These applications did perform their task but there was still a lot of human involvement present here.
- Then comes the rise of the LLMs because of which we have witnessed a huge shift in how we interact with these models LLMs (large language models) are AI systems that can understand, generate output, manipulate, and even respond in a human language.
- As these models are trained on vast data these models are highly capable. These models unlike the previous approaches or models can process and understand information from multiple modalities like text and images.
- This capability has fundamentally transformed image analysis which has resulted in making image analysis making it more accessible and powerful. Earlier to these advancements, image analysis required specialized knowledge and access to sophisticated tools. Now with the help of these LLMs, anyone can upload their image and generate detailed textual description, extract specific information, or even generate creative content based on an image. Also, these LLMs are not restricted to a specific task but can now perform various tasks.
- This advancement has opened up new use cases and ideas for various new applications. For instance, researchers can quickly analyze large datasets of medical images to identify patterns and anomalies. Businesses can automate the extraction of data from visual reports and documents. Also, the multimodal LLMs have significantly improved the accuracy and efficiency of image analysis making them more reliable.
Problem Statement:
- Our research focused on using the capabilities of multimodal LLMs to develop an approach for getting the invoice details in proper JSON format. The invoices contain a number of products their prices and other details and we aimed to fetch each detail from the image invoice.
- The aim was to generate This approach to bridge the gap between visual and textual information, enabling users to easily extract and utilize the valuable insights contained within images.
- The core idea behind our approach is to guide the LLMs with advanced prompt engineering techniques to generate structured text outputs that accurately and comprehensively describe the content of an image.

Step by step guide
Importing libraries:
‘’’
import os
import base64
import google.generativeai as genai
from pathlib import Path
import json
from PIL import Image
import io
genai.configure(api_key="Your_API_Key")
‘’’
OS: It is used to interact with the files from your local system
Base64: It helps to encode and decode binary data into ASCII format
Genai: Provides access to genai models
Pathlib: Offers an object-oriented way to interact with files and directories, making file path handling cleaner.
Json: It helps in dealing with JSON data and is often used for structured data exchange
PIL: This library helps us to manipulate and deal with images
API key: Enter your API key for Gemini
Creating a function that will analyze the image:
‘’’
def generate_data(image_path, prompt):
try:
with open(image_path, 'rb') as img_file:
image_binary = img_file.read()
# Determine the image mime type
image = Image.open(io.BytesIO(image_binary))
image_format = image.format.lower()
content_type = f"image/{image_format}"
# Encode the image as base64 for processing
image_base64 = base64.b64encode(image_binary).decode('utf-8')
# Configure the Gemini model
generation_config = {"temperature": 1,"max_output_tokens": 2000 }
model = genai.GenerativeModel(model_name="gemini-2.0-flash",generation_config=generation_config,)
# Start a chat and send the image for processing
chat = model.start_chat()
response = chat.send_message([
prompt,
{
"mime_type": content_type,
"data": image_base64
}
])
result_text = response.text
return(result_text)
except Exception as e:
return {
"error": f"Error processing image: {str(e)}",
"details": str(e)
}
‘’’- Here we create a function that takes two parameters as input. One is the image path and the second is the prompt. The first major part is to determine the image mime type. (MIME)We find out which format the image is in, whether it’s a jpeg, jpg, or png.
- It's essential to pass this format context to the LLM. Then convert the image into a base64 format. It is essential to convert the image into a base64 because we cannot directly just pass the image and hence we need to convert the image into some sort of data that holds that image information.
- Then we define the model parameters and the models we plan to use. In this case, we are keeping it as Gemini 2.0 Flash. We have defined the value for “temperature” which is how varied a response you are expecting, and the second is “max_output_tokens” where we define the number of maximum output tokens is expected in response.
- Make sure you adjust this parameter correctly otherwise if the response is lengthy and surpasses the “max_output_token” parameter then we won't get a completely generated response.
- Later we create the chat template where we pass the image mime type to the model for context and also the prompt that will guide the model to perform the required task.
- Also, this whole function is inside the “try and except” to ensure the code works as intended and if not presents the error in a systematic manner which makes it more readable and understandable.
Prompt Engineering:
‘’’
prompt = """
Analyze this invoice image and extract the following information in a structured format:
1. Total number of products/items
2. Each product name with its corresponding cost
3. Subtotal amount (if available)
4. Tax amount (if available)
5. Total invoice amount
Return the information in a structured JSON format with the following keys:
{
"total_products": number in integer,
"products": [{"name": "product_1 name", "price": price of product one},{"name": "product_2 name", "price": price of product two} ...],
"subtotal": number,
"tax": number,
"total_amount": number
}
Only respond with the JSON object, nothing else. If any information is not found, use null for that field.
Critical: Only give output in the above format and no explnatory text.
"""
‘’’- To improve the accuracy and reliability of our image analysis, we implemented iterative and advanced prompting. Iterative prompting means guiding the LLM through various clear steps, breaking down complex parts into tasks and manageable tasks.
- eg instead of asking the LLM to directly generate the final analysis, we ask the LLM to first perform some tasks that break down the main goal and then finally give the final analysis.
- Also, in the prompt, we give the sample output of the expected response as well as the format in which it is required. We had to make sure that we were not providing lengthy prompts to the models as if we did it then there is a high chance that the model would start to hallucinate and would start giving garbage or unwanted responses.
- Our research showed that it's important to have a balance of all that is a good number of clear instructions, examples, and other relevant information while still not making the prompt very lengthy. It’s the key to getting the desired output.
- This prompting technique has a lot of potential to further enhance the capabilities of multimodal LLMs, enabling them to perform even more complex and nuanced image analysis. Also, we are putting “Critical” and mentioning that keep the response output in the desired format.
- It's essential to make sure that the very important things are mentioned under this “Critical” so that the LLM model would pay close attention to it and ensure it completes that part.
Generating results:
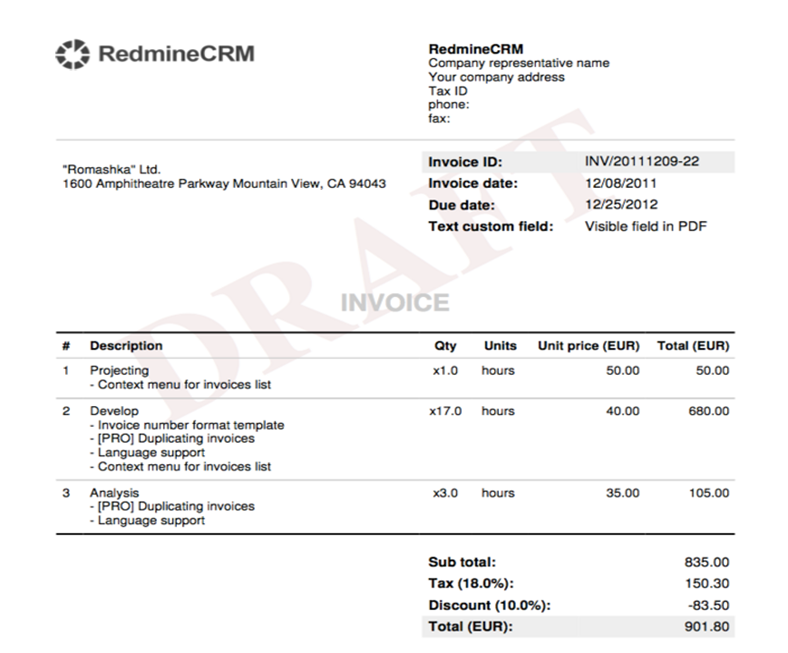
‘’’
image_path = r"Image_path/img.png" # Enter your image path
result = generate_data(image_path, prompt)
print(result)
‘’’
In this step, we call the function by giving the prompt and the image path as parameters. Now that we closely observe the output, we can see we are getting responses as per the desired format, and it is well structured and accurate.
Results:
```json
{
"total_products": 3,
"products": [
{
"name": "Projecting",
"price": 50.00
},
{
"name": "Develop",
"price": 680.00
},
{
"name": "Analysis",
"price": 105.00
}
],
"subtotal": 835.00,
"tax": 150.30,
"total_amount": 901.80
}
```Model Comparison
- For this approach, we experimented with three different models. Those are Gemini 1.5 Pro , and Gemini 2.0 Flash, and The aim was to assess the ability of each of these multimodal how accurately it manages to extract the information from the image.
- Each model was tested against the same prompt. The results were quite shocking. The results showed that all of these three models showed great potential in terms of their image analysis. However, if we analyzed the results for the outputs.
- Observations revealed that Gemini 2.0 Flash managed to get the most consistent results where the image is too complex or has a lot of information to extract. This model managed to give the desired results consistently and in a consistent format.
- Gemini 1.5 Pro was the second best which also terms of results/output matched the accuracy of the Gemini 2.0 Flash but it was slightly less consistent with its response.
- Overall, Our comparative analysis highlighted the strengths and weakness of each model, which as a result provided us with valuable insights into their suitability for different image analysis tasks. Gemini 2.0 Flash emerged as the top performer, demonstrating superior accuracy, reliability, and consistency.
The future of image analysis and AI
- The way AI and these LLMs are evolving we can surely say that we have a promising future where these images become as readily accessible and interpretable as text.
- The time is not far from where the ability of these AI systems to analyze the images and generate minute details may surpass human capabilities in certain domains.
- It won't be shocking if future LLMs not only identify the scene but also grasp the emotional and cultural context behind them.
- Imagine an AI analyzing a painting and it not only describes the elements of that painting but is also able to correctly tell the thought process and intent of the artist. This level of contextual understanding will unlock new possibilities in fields like art history, cultural preservation, and even creative content generation.
- Combining image analysis with other AI fields like natural language processing and audio analysis will lead to stronger and more adaptable systems which can transform the world completely.
At Cogninest AI, we specialize in helping companies build cutting edge AI solutions. To explore how we can assist your business, feel free to reach out to us at team@cogninest.ai