Enhancing Development Efficiency
March 26, 2025· Amol Walunj, Rahul Netkar

AI Engineer on Duty: Automate GitHub Issue Resolution with LLMs
Introduction
Let's face it, no software project is perfect. Bugs, memory leaks, infinite loops, you name it, we've all wrestled with them at 2 AM. Debugging and resolving issues can often feel like a never-ending nightmare, filled with repetitive tasks, head scratching, and countless hours spent wondering why the code suddenly decided to misbehave.

While manual debugging has its merits, it's inherently slow, error prone, and frankly exhausting. What if I told you there's a way to automate this tedious process, dramatically reducing the time you spend chasing elusive bugs?
An automated, AI-powered solution presents an opportunity to streamline and enhance this debugging workflow. By leveraging intelligent automation, developers can spend less time manually identifying and fixing repetitive issues, allowing more focus on innovation and meaningful development tasks.
In this blog, we're going to walk through building an AI-powered GitHub issue solving assistant. You'll learn how to:
Map your repositories intelligently, not blindly.
Generate clear, structured prompts to guide AI accurately.
Apply targeted, automated fixes without breaking your precious code.
Evaluate and benchmark fixes to ensure you're not trading old bugs for shiny new ones.
Project Overview
This project introduces an AI-driven software engineering tool built to automatically resolve issues within a GitHub repository. The system operates through a structured approach comprising three main stages:
- Repository Mapping: Identifying relevant files by analyzing repository structures and issue descriptions.
- AI-Based Fix Generation: Leveraging sophisticated AI models to suggest precise and context aware code modifications.
- Evaluation Pipeline: Applying rigorous tests to validate the correctness and effectiveness of AI-generated patches.
Existing Tools
Modern AI-powered debugging tools are transforming how developers diagnose and fix software issues. Among the notable LLM based debugging tools, Agentless and Aider stand out as two contrasting approaches to AI-assisted debugging. While both leverage large language models (LLMs) to identify and resolve code issues, they differ significantly in their methodologies, integration styles, and levels of user involvement.
Agentless is a fully automated debugging pipeline that operates without interactive agent loops. Instead of requiring developer input throughout the process, it takes an issue description along with a repository and autonomously identifies relevant files, pinpoints the faulty code, and generates candidate patches in a structured manner. The debugging workflow in Agentless follows a deterministic sequence: first, it localizes the error by analyzing the repository structure and finding the most relevant files. Next, it prompts the LLM to generate minimal, precise fixes formatted as unified diffs. Finally, these patches undergo validation, including syntax checks and test execution. This structured approach ensures that only viable fixes are proposed, reducing the likelihood of introducing new bugs. Agentless is particularly effective in repositories with strong test coverage, as it relies heavily on test validation to confirm the correctness of the generated patches. However, it may struggle with ambiguous issues that require human intuition, and its effectiveness depends on the quality of the issue description and available test cases.
In contrast, Aider is an interactive AI debugging assistant designed for command line use. Unlike Agentless, which operates autonomously, Aider requires an active developer in the loop to guide the debugging process. It allows users to chat with an AI model while making real time modifications to a local codebase. Aider seamlessly integrates with Git, automatically committing AI generated changes so developers can track and revert modifications as needed. This tool is particularly useful for iterative debugging, where the developer engages in back and forth dialogue with the AI to refine the fix. One of Aider’s most powerful features is its ability to run test suites and repeatedly refine the code until the tests pass. This allows for a semi-automated debugging cycle where the AI continuously suggests modifications in response to failing test cases. Additionally, Aider supports multiple LLMs, including OpenAI’s GPT-4 and locally hosted models, providing flexibility in deployment. However, because it is a CLI based tool, Aider might present a steeper learning curve for developers unfamiliar with command line workflows, and it lacks the fully autonomous nature of Agentless.
When compared to these tools, the AI debugging system described in this blog shares similarities with Agentless in its structured, automated approach to issue resolution. Like Agentless, it operates in a pipeline fashion, systematically identifying relevant files, generating a patch, and validating it through structured evaluation. However, it introduces several enhancements, including a more sophisticated prompt engineering strategy and repository mapping, which improves file identification accuracy. Additionally, it emphasizes the integration of multiple AI models, making it adaptable to different LLM backends.
While Agentless focuses on a completely hands-off debugging process and Aider provides an interactive, conversational workflow, the AI debugging system in this document aims to bridge these approaches. It is designed to function as an autonomous debugging agent that can be integrated into development pipelines, automatically resolving issues while still allowing for human oversight where necessary. By combining structured debugging methodologies with rigorous validation and extensibility, this system represents an evolution of automated debugging tools, positioning itself as an AI-powered developer assistant that can streamline issue resolution without entirely removing human involvement from the process.
Motivation
The manual debugging process is resource intensive, error prone, and often repetitive, hindering productivity and innovation. Automating this process can lead to:
- Increased Efficiency: Reducing manual effort by automating repetitive debugging tasks.
- Improved Accuracy: Leveraging AI to suggest precise, effective solutions to code issues.
- Higher Quality Software: Systematic validation processes ensuring code reliability and stability.
- Enhanced Productivity: Allowing developers to redirect their focus towards strategic, higher-value tasks rather than routine bug fixing.
By creating this automated tool, developers can harness AI to quickly and accurately resolve code issues, thus elevating the overall development workflow.
By the end of this guide, you’ll have a powerful tool that can identify, analyse, and automatically fix issues, giving you more time to focus on actual innovation and less on firefighting code mishaps.
Let's jump in!
Data Mapping
Before an AI-powered debugging tool can efficiently resolve issues, it must first understand the structure of the repository. Without a well organized mapping system, AI models would be forced to analyze an entire codebase blindly, leading to inefficiency and incorrect results. Repository mapping plays a crucial role in this process by scanning, structuring, and indexing project files. This ensures that AI can quickly locate relevant sections when diagnosing and fixing issues, significantly improving accuracy and performance.
The Purpose of Data Mapping
The primary goal of repository mapping is to provide a structured approach to organizing and indexing code files. To achieve this, the system scans the repository to identify files and directories while filtering out unnecessary files such as logs, binaries, and configuration files. By maintaining a structured file map, the AI can access relevant data efficiently, allowing it to conduct precise searches based on issue descriptions. This prevents unnecessary processing and enhances the accuracy of debugging outcomes.
Implementing the RepoMap Class
At the core of the repository mapping process is the RepoMap class. This class is responsible for scanning directories, filtering relevant files, and creating an organized structure that allows for efficient AI-driven debugging.
Class Initialization
import os
import fnmatch
class RepoMap:
def __init__(self, repo_path, max_file_size=100000000, ignore_patterns=None):
self.repo_path = os.path.abspath(repo_path)
self.root_dir_name = os.path.basename(self.repo_path)
self.max_file_size = max_file_size
self.ignore_patterns = ignore_patterns or [
".github", ".git", "__pycache__", "*.pyc"
]
self.file_map = {}
self.directory_structure = {"dirs": {}, "files": []}
self.build_repo_map()
This initialization process ensures that the repository path is stored in absolute form and prevents processing of large files that could slow down the debugging process. It also sets up a filtering mechanism to exclude irrelevant files and directories. The file_map stores indexed files along with their content, while directory_structure represents the hierarchical organization of the repository.
Building the Data Map
To traverse the repository and extract only useful information, the build_repo_map() method is implemented. This function recursively scans the repository, filtering out ignored files and directories to avoid unnecessary processing. It builds a hierarchical dictionary that represents the project’s structure and stores file contents for future AI analysis.
def build_repo_map(self):
for root, dirs, files in os.walk(self.repo_path):
dirs[:] = [
d for d in dirs if not any(fnmatch.fnmatch(d, pat) for pat in self.ignore_patterns)
]
rel_path = self.normalize_path(os.path.relpath(root, self.repo_path))
if rel_path == ".":
rel_path = ""
current_level = self.directory_structure
path_parts = rel_path.split("/") if rel_path else []
for part in path_parts:
if part not in current_level["dirs"]:
current_level["dirs"][part] = {"dirs": {}, "files": []}
current_level = current_level["dirs"][part]
for file in files:
if not file.endswith(".py") or any(
fnmatch.fnmatch(file, pat) for pat in self.ignore_patterns
):
continue
file_path = os.path.join(root, file)
abs_file_path = os.path.abspath(file_path)
unix_style_path = self.normalize_path(abs_file_path)
current_level["files"].append(file)
if os.path.getsize(file_path) <= self.max_file_size:
with open(file_path, "r", encoding="utf-8", errors="ignore") as f:
content = f.read()
self.file_map[unix_style_path] = content
else:
self.file_map[unix_style_path] = (
f"File too large. Size: {os.path.getsize(file_path)} bytes"
)
This method ensures that only relevant Python files are indexed while maintaining a clean and structured representation of the project. It also avoids unnecessary computation by filtering out large files and non essential content.
Searching for Relevant Files
To make debugging efficient, a search mechanism is implemented within the repository mapping system. This allows the AI model to find relevant files based on a given query.
def search_files(self, query):
relevant_files = []
for file_path, content in self.file_map.items():
if isinstance(content, str) and query.lower() in content.lower():
rel_path = os.path.relpath(file_path, self.normalize_path(self.repo_path))
relevant_files.append(self.normalize_path(rel_path))
return relevant_files
By scanning the indexed files and filtering for matches, this function ensures that only files containing relevant content are retrieved. This targeted approach significantly optimizes AI-driven debugging by narrowing the scope of analysis.
Generating a Repository Overview
For better debugging and AI interaction, a structured overview of the repository can be generated. This helps developers visualize the repository structure and how files are organized.
def get_repo_overview(self):
overview = ["Repository Structure:\n"]
self._add_directory_to_overview(self.directory_structure, "", overview, is_root=True)
return "".join(overview)
Example output of this method:
Repository Structure:
└─ project/
├─ src/
│ ├─ main.py
│ ├─ utils.py
├─ tests/
│ ├─ test_main.py
├─ docs/
│ ├─ README.md
This structured overview helps AI models understand the repository at a glance, enabling efficient debugging workflows.
Why Data Mapping Matters
Without structured repository mapping, AI models would struggle to analyze an entire repository efficiently. They would waste processing power scanning irrelevant files, leading to incorrect fixes and poor debugging outcomes. Additionally, without a structured approach, AI models would lack contextual awareness, making it harder to generate accurate code suggestions.
With a well implemented repository mapping system, AI can precisely locate relevant files, making debugging faster and more accurate. By avoiding unnecessary computation, overall system performance improves. Developers also benefit from better AI-generated fixes, ultimately reducing debugging time and improving productivity.
By laying the foundation for intelligent issue resolution, repository mapping seamlessly integrates AI with structured debugging, making it a crucial component in modern software development workflows.
AI Agent
Introduction
The AI Agent System serves as the core component of our automated debugging tool. It integrates multiple AI models, manages repository access, and orchestrates issue resolution efficiently. By leveraging AI-driven automation, this system helps developers identify relevant files, generate fixes, and ensure that patches are accurately applied. With this advanced automation, the debugging process becomes significantly faster and more efficient.
Purpose of the AI Agent System
The AI Agent System is designed to handle various crucial tasks that enhance debugging efficiency. It interacts with AI models such as GPT-4, Gemini, and Claude to analyze and resolve issues intelligently. Additionally, it manages repository access by cloning and analyzing repositories, ensuring that debugging starts from a well structured foundation.
One of its key roles is generating intelligent prompts that guide AI decision making, allowing models to understand the context of an issue better. Furthermore, it executes issue resolution by generating patches and applying fixes, automating the debugging process and minimizing the need for manual intervention. This not only speeds up issue resolution but also improves code stability and overall development efficiency.
Implementing the AIAgentSystem Class
At the heart of this system is the AIAgentSystem class, which manages repository interactions, AI communication, and issue processing. This class is responsible for ensuring that AI models and repositories interact seamlessly.
Class Initialization
import os
from urllib.parse import urlparse
import git
import google.generativeai as genai
import anthropic
from dotenv import load_dotenv
from agent.prompts import PromptGenerator
from agent.repomap import RepoMap
from agent.utils import *
load_dotenv()
genai.configure(api_key=os.getenv("GOOGLE_API_KEY"))
openai_key = os.getenv("OPENAI_API_KEY2")
anthropic_key = os.getenv("ANTHROPIC_API_KEY")
class AIAgentSystem:
def __init__(self, model_name="gpt-4o-2024-08-06"):
self.model_name = model_name
self.repo = None
self.repo_path = None
self.repo_map = None
self.prompt_generator = PromptGenerator()
self.gpt4o_client = CustomOpenAI(api_key=openai_key)
self.json_model = genai.GenerativeModel(model_name="gemini-1.5-pro-002")
self.normal_model = genai.GenerativeModel(model_name="gemini-1.5-pro-002")
print(f"Initialized AIAgentSystem with model: {model_name}")
This initialization sets up AI models for generating both textual and structured JSON responses. It also manages repository cloning and file mapping while ensuring secure API access through environment variables. With this setup, the AI system is ready to process repository data and assist with debugging.
Cloning and Accessing Repositories
To analyze code effectively, the system must access and process repositories. This is achieved through a function that clones repositories and initializes structured analysis.
def get_or_clone_repo(self, repo_url, commit_hash=None):
parsed_url = urlparse(repo_url)
repo_name = os.path.basename(parsed_url.path).rstrip(".git")
base_dir = os.path.join(os.getcwd(), "cloned_repos")
os.makedirs(base_dir, exist_ok=True)
self.repo_path = os.path.abspath(os.path.join(base_dir, repo_name))
if os.path.exists(self.repo_path):
self.repo = git.Repo(self.repo_path)
if commit_hash:
self.repo.git.checkout(commit_hash)
else:
self.repo = git.Repo.clone_from(repo_url, self.repo_path)
if commit_hash:
self.repo.git.checkout(commit_hash)
self.repo_map = RepoMap(self.repo_path)
return self.repo_path
This function ensures that repositories are only cloned if they are not already available. If a specific commit hash is provided, it checks out the corresponding commit for a precise debugging context. Once the repository is ready, the system initializes RepoMap, which structures the repository for easier AI analysis.
Generating AI Responses
To interact with AI models and generate useful responses, the system formats prompts and queries the AI models.
def generate_response(self, prompt):
messages = [{"role": "user", "content": prompt}]
response = self.gpt4o_client.chat_completions_create(
model=self.model_name, messages=messages, temperature=0.3
)
return response.choices[0].message.content
This function allows the system to construct structured prompts and retrieve AI-generated responses. With properly formatted queries, AI models can provide better and more relevant debugging insights.
Identifying Relevant Files
Once an issue is described, the AI Agent System must determine which files are most relevant to resolving it.
def find_relevant_files(self, root, issue_description):
repo_overview = self.repo_map.get_repo_overview()
prompt = self.prompt_generator.get_find_relevant_files_prompt(root, repo_overview, issue_description)
response = self.generate_response(prompt)
return extract_file_paths(response)
This function creates an AI-driven prompt that helps identify the most relevant files for a given issue. The AI then generates a response that includes potential file paths, which are extracted and used for further debugging analysis.
Processing an Problem
When a developer submits an issue for debugging, the AI Agent System processes it by following a structured approach.
def process_issue(self, repo_url, issue_description, commit_hash=None):
repo_path = self.get_or_clone_repo(repo_url, commit_hash)
relevant_files = self.find_relevant_files(repo_path, issue_description)
most_relevant_file = self.get_most_relevant_file(relevant_files, issue_description)
instructions = self.generate_instructions(issue_description)
return self.generate_repair(most_relevant_file, self.repo_map.get_file_content(most_relevant_file), instructions)
The system first clones the repository and retrieves a structured file map. It then finds the most relevant file for the given issue and generates AI driven repair instructions. Finally, it applies an intelligent patch to modify the file, streamlining the debugging process and reducing manual effort.
Problem Processing
Introduction
Issue processing is a crucial stage in our AI-driven debugging tool. This phase involves analyzing an issue description, identifying relevant files, generating structured repair instructions, and applying patches. By automating these tasks, we streamline debugging workflows, reducing manual intervention while improving code quality and efficiency.
The process_issue() Method
The process_issue() method is responsible for orchestrating the issue resolution process. It ensures that repositories are properly accessed, relevant files are identified, and AI-generated fixes are applied in a structured manner.
Code Implementation
def process_issue(self, repo_url, issue_description, commit_hash=None):
print(f"\n{'='*50}\nProcessing issue: {issue_description}")
repo_path = self.get_or_clone_repo(repo_url, commit_hash)
if not repo_path:
return "Failed to clone or access the repository."
print(f"Repo path: {self.repo_path}")
relevant_files = self.find_relevant_files(self.repo_path, issue_description)
most_relevant_file = self.get_most_relevant_file(relevant_files, issue_description)
self.og_content = self.repo_map.get_file_content(most_relevant_file)
original_file_content = self.repo_map.get_file_content(most_relevant_file)
instructions = self.generate_instructions(issue_description)
print(f"\nInstructions:\n{instructions}\n")
patch = self.generate_repair(most_relevant_file, original_file_content, instructions)
if patch:
print(f"\nGenerated patch for {most_relevant_file}:")
print(patch)
return patch
else:
print(f"\nNo changes were necessary for {most_relevant_file}")
return None
This method follows a structured approach:
- It clones or accesses the repository, ensuring the correct commit is checked out.
- AI models analyze the issue description to identify relevant files.
- It generates structured repair instructions based on AI analysis.
- A patch is created and applied, with changes tracked using a git diff output.
Generating Fix Instructions
Once the most relevant file is identified, the system generates AI-driven repair instructions. These instructions guide modifications to resolve the issue effectively.
Code Implementation
def generate_instructions(self, issue_description):
prompt = self.prompt_generator.get_fix_instructions_prompt(issue_description, self.og_content)
response = self.generate_response(prompt)
return response
This function ensures:
- A detailed AI prompt is constructed using the issue description and file content.
- The AI model provides structured repair steps tailored to the specific problem.
- Developers receive clear modification instructions that improve code accuracy
Applying the Patch
With AI-generated i nstructions in hand, the next step is applying the fix and generating a structured git diff patch.
Code Implementation
def generate_repair(self, file_path, og_content, instructions):
ne_content = copy.deepcopy(og_content)
prompt = self.prompt_generator.get_repair_prompt(instructions, ne_content)
correction = self.generate_response(prompt)
extraction_prompt = self.prompt_generator.extract_repair_code_prompt(correction)
extracted_resp = self.generate_json_response(extraction_prompt)
extracted_block = ast.literal_eval(extracted_resp)
for fix in extracted_block["fixes"]:
search_term = fix["search"]
replace_term = fix["replace"]
line_interval = find_search_term_interval(ne_content, search_term)
if line_interval:
ne_content = replace_search_term(ne_content, search_term, replace_term, line_interval)
relative_path = os.path.relpath(file_path, self.repo_path)
diff = fake_git_repo("fake_repos", relative_path, og_content, ne_content)
return diff
This method follows a structured patching workflow:
- The AI model generates and extracts relevant repair code.
- The affected code block is identified, and modifications are applied.
- A git diff patch is created to systematically track changes.
Helping Functions for Code Validation
To maintain accuracy and prevent errors, the system uses several utility functions:
- find_search_term_interval(): Determines where changes need to be applied within the code.
- replace_search_term(): Updates the affected code while maintaining proper indentation.
- check_file_syntax(): Ensures that modified code does not introduce syntax errors.
- fake_git_repo(): Simulates a Git repository to generate a structured git diff output.
Example of a Generated git diff Patch
--- src/data_handler.py
+++ src/data_handler.py
@@ -34,6 +34,7 @@
processed_data = compute_results(data)
store_data(processed_data)
+ del data # Prevent memory leak
return processed_data
Prompt Engineering
Introduction
Effective prompt engineering is a crucial aspect of guiding AI models to produce accurate and relevant outputs. In our AI-driven debugging system, well designed prompts ensure that the AI correctly identifies relevant files, generates structured instructions, and applies precise code modifications. By reducing ambiguity and refining AI interactions, we can improve the accuracy and efficiency of automated debugging workflows.
The PromptGenerator Class
The PromptGenerator class plays a vital role in dynamically constructing prompts for various tasks in the debugging workflow. These prompts help structure AI interactions, ensuring that responses are both meaningful and actionable.
Generating File Identification Prompts
To help AI models locate relevant files, we generate structured prompts that provide repository context and issue descriptions.
Code Implementation
@staticmethod
def get_find_relevant_files_prompt(root, repo_overview, issue_description):
return f"""
Root directory: ### {root} ###
Repository Structure:
{repo_overview}
Issue Description:
---BEGIN ISSUE---
{issue_description}
---END ISSUE---
Instructions:
Identify the most relevant files related to the issue. List at most 10 files in order of relevance.
Output should be a newline separated list wrapped in triple backticks.
"""
This method ensures:
- The AI model receives repository context, helping it understand the project's structure.
- The output remains concise and limited to relevant files, reducing unnecessary noise.
- A standardized format is maintained for consistency in responses.
Generating Issue Rephrasing Prompts
Before suggesting fixes, AI models need to correctly interpret the issue description. A structured rephrasing prompt extracts key details and refines the problem statement.
Code Implementation
@staticmethod
def get_issue_rephrased_prompt(issue):
return f"""
Issue description:
---BEGIN ISSUE---
{issue}
---END ISSUE---
Extract key points and summarize what needs to be fixed.
Present response in a structured markdown format.
"""
This function:
- Focuses on the most critical aspects of the issue to help AI models process information more effectively.
- Ensures AI interprets the problem correctly before generating a response.
Generating Fix Instructions Prompts
Once an issue is identified, the AI model must generate step-by-step modification instructions. These prompts combine the issue description with the affected code to ensure relevant and actionable responses.
Code Implementation
@staticmethod
def get_fix_instructions_prompt(issue, file_content):
return f"""
File content:
---BEGIN CONTENT---
{file_content}
---END CONTENT---
Issue description:
---BEGIN ISSUE---
{issue}
---END ISSUE---
Provide step-by-step modification instructions to resolve the issue.
"""
Key benefits of this approach:
- The AI model has full context, reducing the chances of generating incorrect fixes.
- It guides the AI toward providing specific and structured fixes rather than vague recommendations.
Generating Repair Prompts
For AI-generated fixes to be correctly applied, they must be structured in a way that maintains code formatting and indentation. The repair prompt ensures consistency in how fixes are implemented.
Code Implementation
@staticmethod
def get_repair_prompt(instruction, file_content):
return f"""
File content:
---BEGIN CODE---
{file_content}
---END CODE---
Instruction:
---BEGIN INSTRUCTION---
{instruction}
---END INSTRUCTION---
Implement the changes using SEARCH and REPLACE blocks with proper indentation.
This method ensures:
- AI-generated responses follow a structured format, making them easier to apply programmatically.
- Code indentation and structure remain intact, reducing errors in applied fixes.
By focusing on well structured prompts, we maximize the effectiveness of our AI debugging system, making issue resolution faster, more accurate, and highly automated.
Helping Functions
Introduction
Utility functions play a crucial role in ensuring the smooth execution of our AI-powered debugging system. These functions handle key operations such as token counting, syntax validation, search and replace logic, and patch generation. By automating these repetitive tasks, we improve efficiency, accuracy, and reliability, making AI-driven debugging seamless and effective.
Managing AI Token Usage
To optimize AI interactions and prevent exceeding API token limits, we implement a function for calculating the number of tokens in a given text.
Code Implementation
def calculate_tokens(text):
encoding = tiktoken.get_encoding("cl100k_base")
return len(encoding.encode(text))
This function:
- Encodes text using OpenAI’s tokenizer (cl100k_base).
- Counts the number of tokens in the provided input.
- Prevents exceeding API token limits, ensuring cost effective AI calls.
Checking Code Syntax
Before applying AI-generated fixes, it's essential to validate the syntax of the modified code.
Code Implementation
def check_file_syntax(file_content):
try:
ast.parse(file_content)
return True
except SyntaxError:
return False
This function:
- Parses Python code to check for syntax errors before applying AI fixes.
- Ensures AI-generated modifications do not introduce broken code.
Finding and Replacing Code Segments
AI-driven debugging requires precise identification of affected code blocks and accurate replacements.
Code Implementation
def find_search_term_interval(file_content, search_term):
content_lines = file_content.splitlines()
for i, line in enumerate(content_lines):
if line.strip() == search_term.strip():
return [i + 1, i + len(search_term.splitlines())]
return None
def replace_search_term(file_content, search_term, replace_term, line_interval):
content_lines = file_content.splitlines()
content_lines[line_interval[0] - 1: line_interval[1]] = replace_term.splitlines()
return "\n".join(content_lines)
These functions:
- Locate exact code positions where AI modifications should be applied.
- Replace the identified block while preserving indentation and formatting.
Generating Git Style Patches
To maintain version control and track AI-generated modifications, we simulate Git operations to create structured git diff patches.
Code Implementation
def fake_git_repo(repo_playground, file_path, old_content, new_content):
with tempfile.TemporaryDirectory(dir=repo_playground) as temp_dir:
full_file_path = os.path.join(temp_dir, file_path)
os.makedirs(os.path.dirname(full_file_path), exist_ok=True)
with open(full_file_path, "w") as f:
f.write(old_content)
subprocess.run(["git", "init"], cwd=temp_dir)
subprocess.run(["git", "add", file_path], cwd=temp_dir)
subprocess.run(["git", "commit", "-m", "initial commit"], cwd=temp_dir)
with open(full_file_path, "w") as f:
f.write(new_content)
git_diff = subprocess.run(["git", "diff", file_path], cwd=temp_dir, capture_output=True, text=True)
return git_diff.stdout
This function:
- Creates a temporary Git repository to track changes.
- Stores original and modified content within Git to generate structured git diff patches.
- Provides a reviewable format before applying AI-generated modifications.
Example Workflow
Given the original code snippet:
for i in range(10):
print(i)
AI-generated fix:
--- script.py
+++ script.py
@@ -1,2 +1,2 @@
for i in range(10):
- print(i)
+ logging.info(i)
Steps:
1. The matching snippet is located using find_search_term_interval().
2. The identified code is replaced using replace_search_term().
3. The modified code is validated using check_file_syntax().
4. A git diff patch is generated using fake_git_repo().
Running the System
Introduction
After setting up all the components, the final step is to execute the AI-powered debugging tool in a structured manner. Running the system involves setting up dependencies, initializing the AI agent, processing issues, and validating the generated patches. By following a systematic approach, we ensure that AI-driven debugging is efficient and reliable.
Step 1: Setting Up the Environment
Before executing the system, it is essential to install all required dependencies to ensure smooth operation.
Code Implementation
pip install -r requirements.txt
This command:
- Installs necessary libraries, including gitpython, openai, google-generativeai, anthropic, and others.
- Ensures that all dependencies are in place before running the debugging system.
Step 2: Initializing the AI Agent
The AI Agent must be instantiated with the appropriate model before it can process issues.
Code Implementation
agent = AIAgentSystem(model_name="gpt-4o-2024-08-06")
This step:
- Loads the AI model that will handle issue resolution.
- Prepares the AI agent for executing debugging tasks efficiently.
Step 3: Processing an Problem
Once initialized, the system can begin processing issues by retrieving repository data, analyzing the issue description, and generating a patch.
Code Implementation
repo_url = "https://github.com/example/repo.git"
issue_description = "Fix the function causing memory leaks."
commit_hash = None# Optional, can be specified if needed.
patch = agent.process_issue(repo_url, issue_description, commit_hash)
print(patch)This function:
- Provides the repository URL from which the issue will be analyzed.
- Defines the issue description to guide AI-driven debugging.
- Calls process_issue() to generate a patch with AI-suggested modifications.
Step 4: Validating the Patch
Before applying the AI-generated patch, it must be tested to ensure it does not introduce syntax errors.
Code Implementation
if check_file_syntax(patch):
print("Patch is syntactically correct!")This step:
- Runs a syntax validation check to prevent introducing errors into the repository.
- Ensures the AI-generated patch is safe before application.
Step 5: Submitting the patch for evaluation
To assess the effectiveness of the AI-generated patches, we run the system through a structured evaluation pipeline that leverages the SWE bench lite dataset (Hugging Face Link). This dataset provides real-world software engineering issues sourced from GitHub, including relevant metadata such as:
- instance_id: A unique identifier for each issue (e.g.,
repo_owner__repo_name-PR-number). - patch: The original patch from the corresponding PR, excluding test-related code.
- repo: The repository from which the issue originates.
- base_commit: The commit hash before the patch was applied.
- problem_statement: The issue title and description.
- FAIL_TO_PASS & PASS_TO_PASS: Lists of test cases affected by the patch.
We processed a random set of 20 issues from this dataset and evaluated them using the Moatless-Evaltool (GitHub Link). This tool requires submitting a JSONL file containing each instance and its corresponding AI-generated patch.
JSONL Format for Evaluation
Before submission, we format the generated patches into a structured JSONL file, where each line contains metadata and the patch details:
{"instance_id": "example_repo__12345", "model_patch": "diff --git a/file.py b/file.py\nindex abc123..def456 100644\n--- a/file.py\n+++ b/file.py\n@@ -10,7 +10,7 @@ def function():\n- old_code()\n+ new_code()\n", "model_name_or_path": "swe_agent"}
{"instance_id": "another_repo__67890", "model_patch": "diff --git a/module.py b/module.py\nindex xyz789..uvw000 100644\n--- a/module.py\n+++ b/module.py\n@@ -20,3 +20,3 @@ def fix():\n- buggy_line()\n+ fixed_line()\n", "model_name_or_path": "swe_agent"}
This structured format ensures compatibility with Moatless Evaltool, enabling systematic evaluation of how well the AI-generated patches resolve real-world issues.
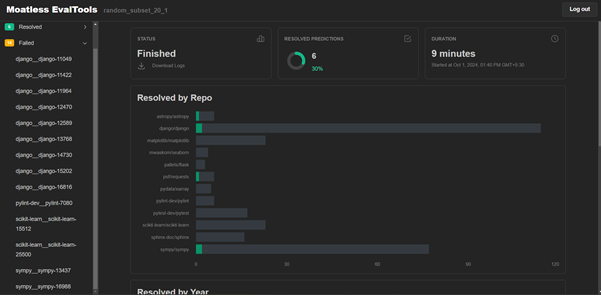
The execution process involves:
- Installing dependencies to set up the environment.
- Initializing the AI agent with the correct model for debugging.
- Processing issues by fetching repository data and generating fixes.
- Validating patches to ensure correctness before applying them.
- Submitting patches for external evaluation to measure effectiveness.
Results
Evaluation Performance
- The AI-powered debugging system was tested on 20 randomly sampled examples from the SWE Bench Lite test set due to API constraints.
- The system successfully resolved 6 out of 20 problems, achieving an accuracy of 30%.
- One key observation was that the file identification process was a major limiting factor. Out of the 14 failed examples, 7 failures were attributed to incorrect file selection.
Stage 1 vs. Stage 2 Performance
- To further investigate, the 7 incorrect file identification cases were re-evaluated by manually hardcoding the correct file and running only Stage 2 (fix generation).
- In this controlled setting, the system correctly resolved 2 out of 7 issues, meaning that Stage 2 (fix generation) had an accuracy of 40% when provided with the correct file.
- This highlights that while the modification generation is relatively effective, improving file identification could significantly boost overall accuracy.
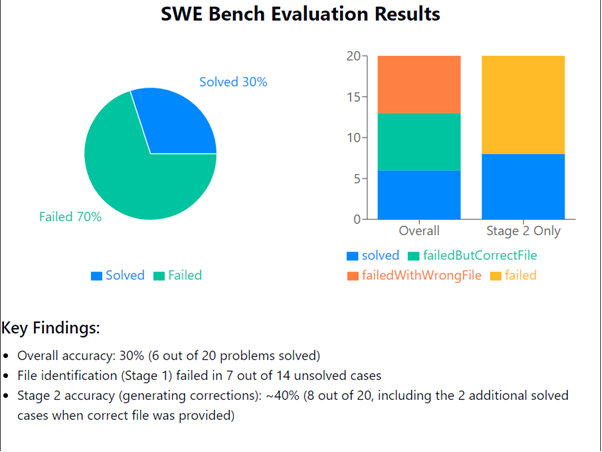
Insights from Error Analysis
- The system performs well when the issue is localized within a single, clearly defined file.
- Errors primarily stem from selecting incorrect files when analyzing large repositories.
- Refining the repository scanning process and incorporating better heuristics for identifying relevant files is a promising next step for improving results.
Summary of Findings
- Overall Accuracy: 30% (6/20 problems solved correctly)
- File Identification Success Rate: 50% (7/14 incorrect cases due to wrong file selection)
- Fix Generation Accuracy (Given Correct File): 40% (2/7 additional problems resolved)
- Future Improvement Focus: Enhancing file selection strategies to improve Stage 1 accuracy.
Conclusion and Future Improvements
Summary of Key Benefits
The AI-powered software engineering tool provides a structured, automated approach to identifying, analyzing, and resolving issues in a codebase. By integrating AI models with repository mapping, structured prompt generation, and robust evaluation pipelines, this system streamlines debugging and accelerates issue resolution.
Key benefits include:
- Automated Issue Resolution: Reduces manual debugging effort.
- Intelligent Code Fixes: AI-driven insights ensure precise modifications.
- Structured Evaluation: Validates patches through rigorous testing and benchmarking.
- Scalable and Adaptable: Supports multiple AI models and extensible workflows.
Future Improvements
While the system provides significant automation and efficiency gains, several areas can be further improved:
1. Enhancing File Identification Accuracy
- Refining AI prompts to improve file selection precision.
- Incorporating semantic analysis to detect relevant files beyond keyword matching.
2. Improving Prompt Engineering
- Adaptive prompt refinement using reinforcement learning techniques.
- Generating more context aware instructions to enhance AI response quality.
3. Multi-Agent Collaboration for Patch Improvement
- Combining outputs from multiple AI models to validate and refine patches.
- Introducing voting mechanisms where different models rank suggested fixes.
4. Expanding Support for More Programming Languages
- Training AI models on diverse codebases beyond Python.
- Building specialized handling for Java, JavaScript, and C++ projects.
5. Automated Functional Testing and CI/CD Integration
- Automating test execution to verify AI-generated patches.
- Integrating AI-generated patches with continuous integration pipelines for real-time validation.
Final Thoughts
This AI-driven debugging system represents a significant step toward automated software engineering. While current implementations provide tangible efficiency gains, future enhancements can push the boundaries further. By integrating adaptive learning, improved prompt engineering, and multi agent collaboration, AI-powered debugging can become an indispensable tool for software developers.
With ongoing refinements, this system has the potential to revolutionize how engineers detect, analyze, and fix code issues, reducing development cycles and improving overall software quality.
References:
- Agentless - https://github.com/OpenAutoCoder/Agentless
- Aider - https://github.com/Aider-AI/aider
- SWE bench - https://www.swebench.com/
- SWE bench github - https://github.com/SWE-bench/SWE-bench
- SWE-bench-lite dataset - https://huggingface.co/datasets/princeton-nlp/SWE-bench_Lite
- Moatless-Evaltool - https://github.com/aorwall/moatless-tools
At Cogninest AI, we specialize in helping companies build cutting edge AI solutions. To explore how we can assist your business, feel free to reach out to us at team@cogninest.ai